Theodo France

Explorez leurs posts
Parcourez les posts publiés par l’entreprise pour une immersion dans leur culture et leurs domaines d’expertise.

Le concours Petit Poucet 2026 a ouvert ses candidatures !
https://petitpoucet.wiin.io/fr/ 🔥 Le Concours Petit Poucet ouvre ses candidatures pour l’édition 2026 jusqu’au 10 avril ! Fondé en 2002, le concours d’entrepreneuriat étudiant Pet…
19/01/2026
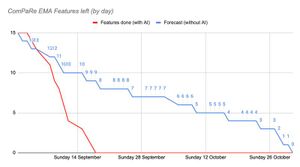
How I Shipped 2 Months of Features in 3 Weeks With LLM Agents (and What It Means for Engineering Leaders)
In three weeks, I pushed 15 brand-new features into production for ComPaRe EMA, the mobile app we’re building for AP‑HP. Without LLM agents, that same backlog would have taken two…
03/10/2025

REX après la migration d’une feature Android/iOS vers KMP
Dans un premier article, nous avons exploré comment migrer progressivement une application native Android/iOS vers Kotlin Multiplatform (KMP). Si vous avez suivi ce guide, vous ave…
04/07/2025

ShedLock : Gérer efficacement les tâches planifiées dans une architecture multi-instances
Introduction Pour les applications d'entreprise, en 2025 l’exécution de tâches planifiées est un besoin courant : génération de rapports, traitements par lots, synchronisation de d…
04/07/2025

Theodo Named 2025 Google Cloud Services Partner of the Year
Las Vegas, April 8, 2025 Theodo today announced that it has received the 2025 Google Cloud Services Partner of the Year. Theodo is being recognized for its achievements in the Goog…
04/07/2025

How QRQC helps me better manage bugs on my project?
As a software developer, you spend most of your time delivering code and then fixing bugs you introduced in your code. The Pareto principle is a great way to represent our day-to-d…
04/07/2025

How we migrated from AWS Glue to Snowflake and dbt
Today, I’ll tell you about our ETL migration from AWS Glue to the Snowflake and dbt modern data stack. My team’s mission is to centralize and ensure data reliability from multiple…
04/07/2025

Sécuriser les partages Notion : guide pour tous
Chez Theodo Fintech, nous avons fait de Notion notre QG digital. Documentation produit, projets tech, comptes rendus, référentiels clients ou financiers… tout y passe. Et c’est bie…
04/07/2025

S’affranchir du legacy et libérer l’innovation grâce à l’IA
Nous modernisons vos systèmes legacy jusqu’à 3 fois plus vite grâce à une IA maîtrisée. Une approche robuste pour faire de votre IT un levier stratégique au service de vos ambition…
22/12/2025

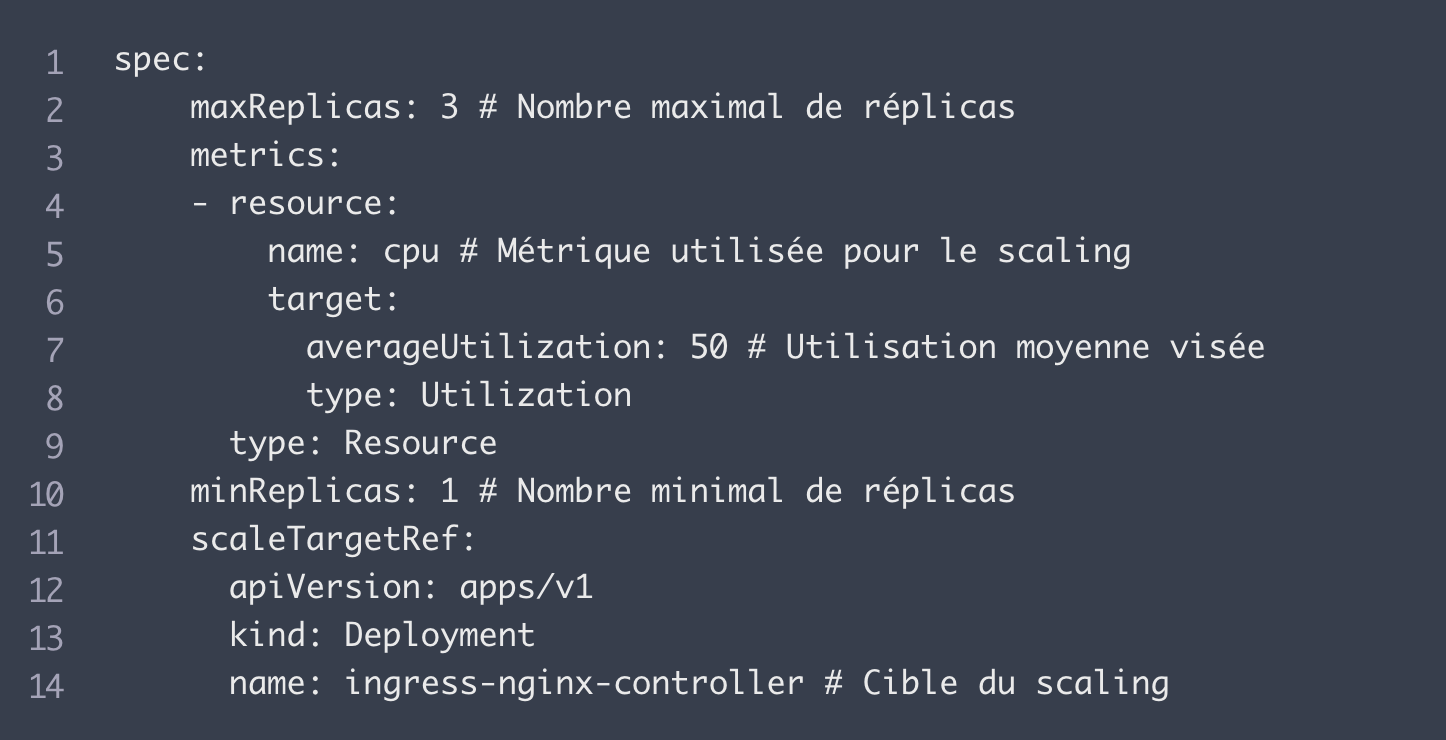
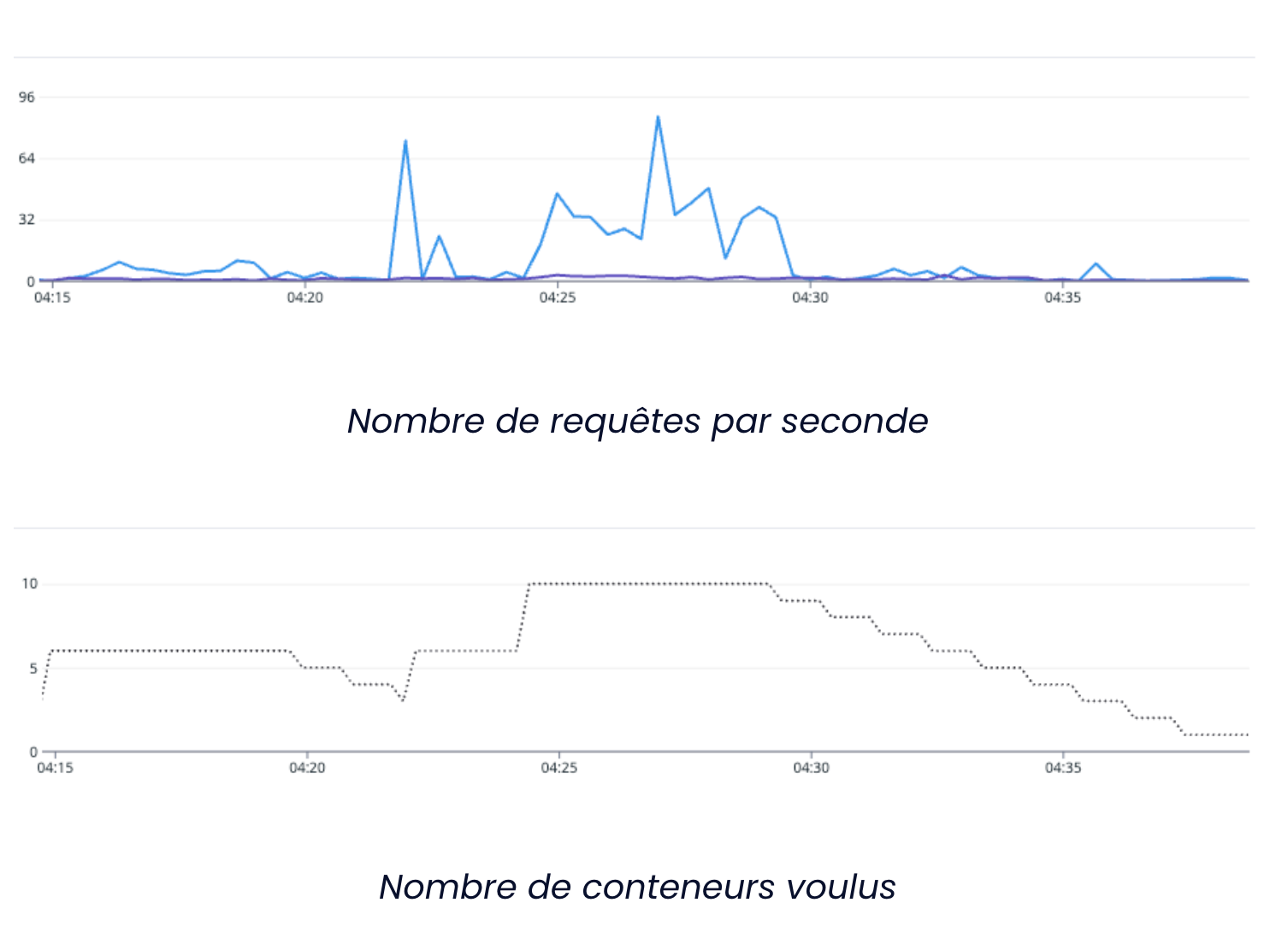
Qu’est-ce que le scaling ?
Une bonne application est une application qui tient sa charge d’utilisateurs, notamment grâce à un scaling controlé. Dans cet article nous aborderons ce sujet, et plus particulière…
04/07/2025

How LLM Monitoring builds the future of GenAI ?
Discover how Langfuse offers secure, open-source monitoring for LLM and GenAI solutions. Large Language Models (LLMs) are popping up everywhere and are more accessible than ever. W…
04/07/2025

Les annotations java custom pour respecter l’architecture hexagonale
Le problème que l’on veut résoudre Lorsque l’on développe une API avec Spring Boot, il est fréquent d’utiliser les annotations fournies par le framework, telles que @Service, @Comp…
04/07/2025

Shingo Publication Award
🎉 Theodo a le plaisir d’annoncer que The Lean Tech Manifesto a reçu le Shingo Publication Award, la distinction la plus prestigieuse du monde du Lean Thinking. Après plus de quatr…
22/12/2025

Faites des Plugins pas la Guerre: REX sur ma bataille pour écrire un plugin
Imaginez commencer chaque projet avec tous les outils configurés et prêts à l’emploi. Le rêve, non ? En tant que développeur Android, j’ai toujours eu à portée de main les outils n…
04/07/2025

Don’t use Langchain anymore : Atomic Agents is the new paradigm !
Introduction Since the rise of LLMs, numerous libraries have emerged to simplify their integration into applications. Among them, LangChain quickly established itself as the go-to…
04/07/2025

Optimize Your Google Cloud Platform Costs with Physical Bytes Storage Billing
In today's data-driven world, cloud providers are essential for efficiently managing, processing, and analyzing vast amounts of data. When choosing one such provider, Google Cloud…
08/04/2025