Today, I’ll tell you about our ETL migration from AWS Glue to the Snowflake and dbt modern data stack. My team’s mission is to centralize and ensure data reliability from multiple business domains. We build an analytical foundation to support product and strategic teams' decision-making. As part of this effort, we migrated 28 gold models that power 13 data products, including dashboards, profiling tools, and analytical studies. These models serve as a cornerstone for enabling data-driven insights.
Initial situation : a degraded work environment
The lack of documentation and governance made errors difficult to log and trace. Also, there was no proper development environment: Each change posed a risk to production, leading to constant stress for developers.
Data transformations were done on AWS Glue with Spark SQL, complex tasks that required a time-consuming environment to set up. It made it impossible to test data quality during development.
All users had the same level of access to data, regardless of their role within the organization. This lack of access control made managing permissions unclear. It was impossible to ensure proper data security.
A Welcome Migration
We opted for a Data stack combining dbt and Snowflake. This solution provides dedicated environments, data quality tests, and integrated documentation via dbt as code. It also enables enhanced data governance. dbt is a framework for data transformations, quality and documentation and Snowflake is a cloud-based data warehouse.
The Impact on Data Engineers’ Daily Work
As Data Engineers, we undertook the migration of all transformations to automate data processes such as cleaning and transforming data, while also rebuilding dashboards and KPIs shared with our clients.
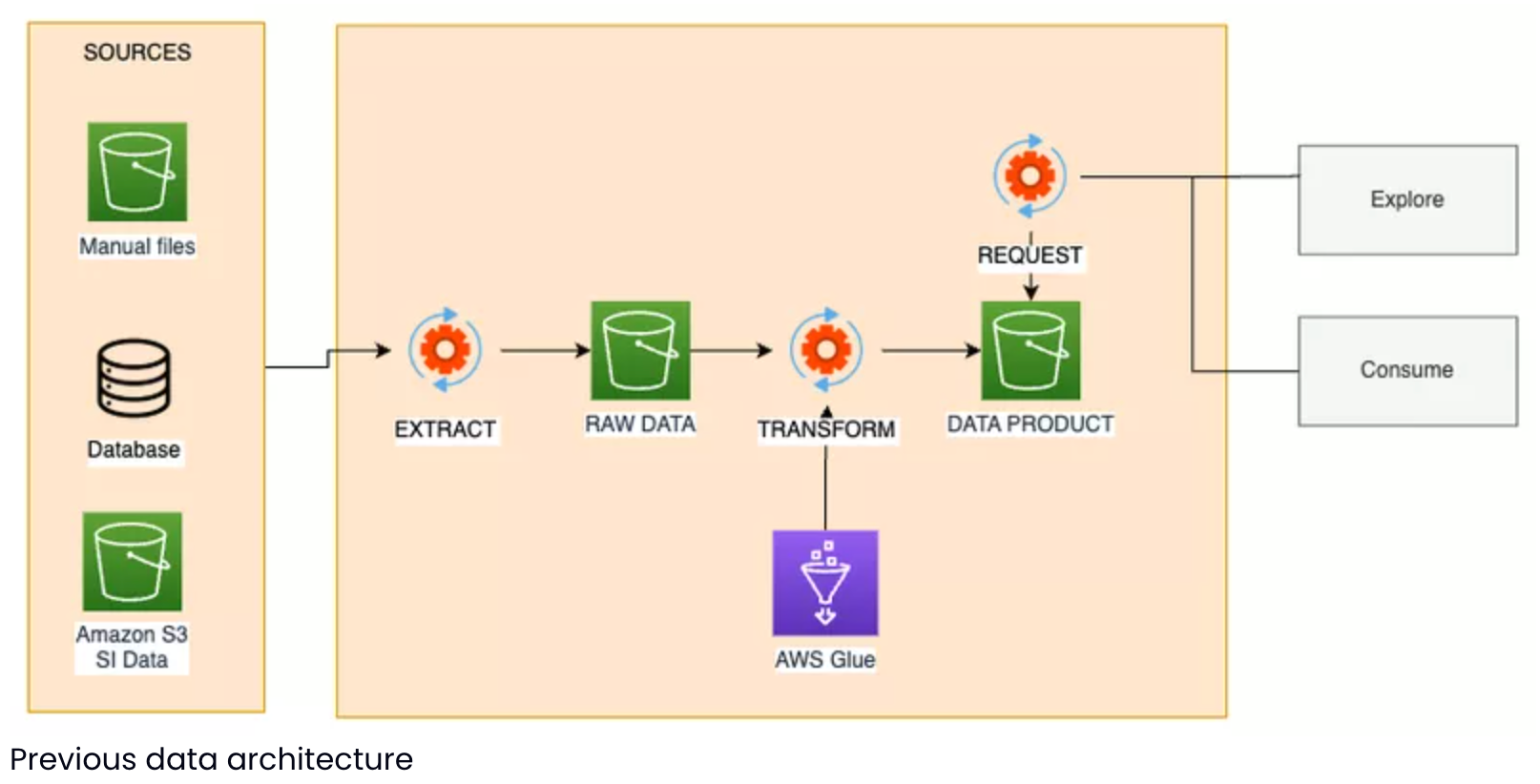
The Previous Solution
Each transformation was stored in a Git repository and duplicated on AWS as Glue jobs. These Python jobs used a Spark environment and were orchestrated in AWS Workflows. All the data within the medallion architecture was stored in the AWS Glue Data Catalog.
To test each transformation, I ran the scripts directly in production, without CI/CD. Each developer had to install a Jupyter Notebook and a Glue PySpark kernel, which took about 40 seconds to initialize. This process was our only way to iterate quickly and validate the completeness and accuracy of data transformations. The lack of CI/CD prevented us from detecting errors before production deployment 😈
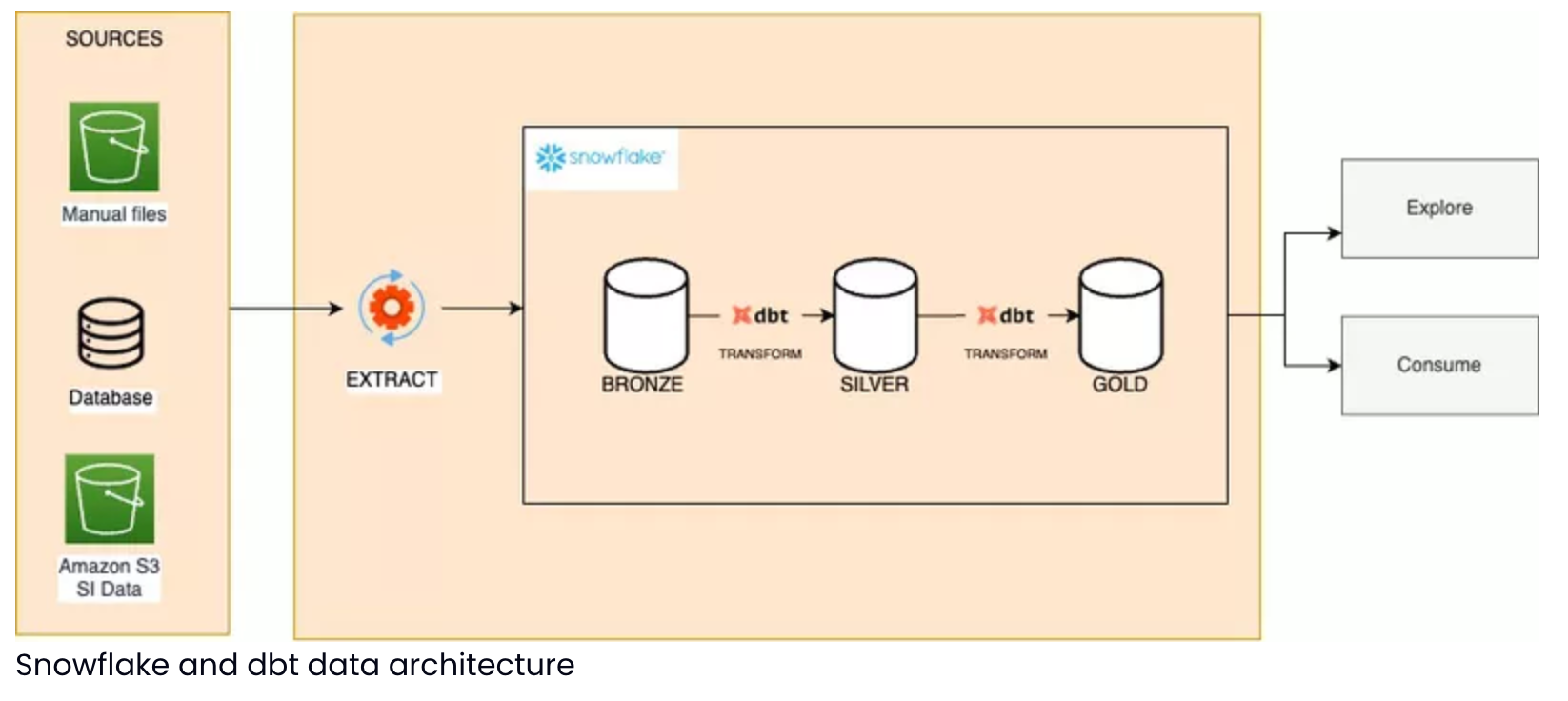
The New Solution
With dbt, I was able to document our entire data architecture using its documentation as code. I was also able to implement quality tests and unit tests to validate our transformations and detect bugs. It became possible to preview the data, test model execution, and view data lineage through the dbt power user extension. And all of this on a dedicated development environment for our entire medallion architecture!
Finally, Snowflake offered us more precise resource control through its Billing and Cost Management tool, allowing for consumption and cost optimization. Compared to AWS Glue, which can lead to high costs due to auto-scaling, we expect a reduction in our infrastructure costs.
Preparation: Mapping and Planning the Migration
Our migration began with setting up the Snowflake environments and access. We built the dbt repository and distributed Snowflake user access based on their roles.
The Iso-functional Migration of Data Products
Break everything and rebuild it? 🧐 How to ensure we didn’t forget any data model? 😱 How can we reassure Justine her dashboard is still reliable? How do we explain Thomas his key metric is now multiplied by 5?
We froze and listed the entities that have to be migrated and described them according to the medallion architecture to eliminate these risks. Our solution architecture consists of data in Bronze, Silver, and Gold states (classic ETL) and dashboarding and KPI products consumable in Qlik and Metabase. It felt hard to list everything we would need to migrate, but without that, we’d have no control over the migration and no way to measure it.
Our strategy:
Migrate the Bronze → Silver transformations
Once the Silver layer is reliable, migrate the Silver → Gold transformations
Once the Gold layer is reliable, migrate dashboards
For each entity to migrate, we had to capture the existing behavior and validate the equivalence of the reproduced model using the Golden Master refactoring strategy. We modularized the transformations using Data Modeling: an excellent source of documentation that helped us understand the analytical work challenges and allowed us to do things quickly and efficiently.
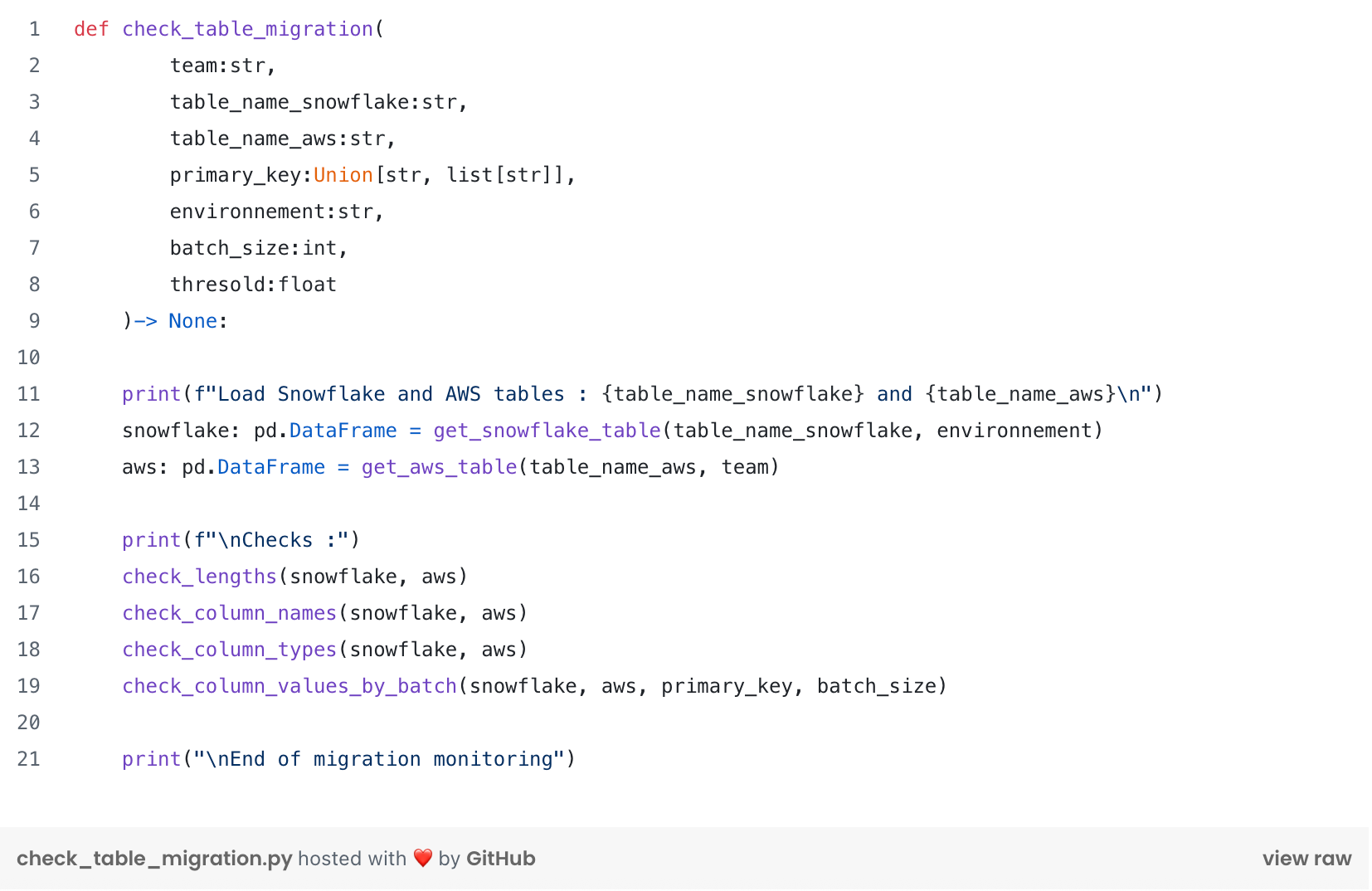
We transcribed the Python scripts using Spark SQL into Snowflake SQL models in dbt. For each model, we used an in-house 🏠 migration monitoring script. This script allowed us to compare the migrated data with the source data. The following script connects to both AWS and Snowflake environments and compares the dataframes!
Deep dive into dbt challenges and solutions
In practical terms, how did it go for the Data Engineers? Migrating the transformations was pretty easy. The real challenge was understanding and justifying the differences found once the models were migrated.
We had to interview the users of the legacy models. The code was poorly understood and lacked documentation. Some models were discarded, while others were rebuilt by redefining the needs of the consumers.
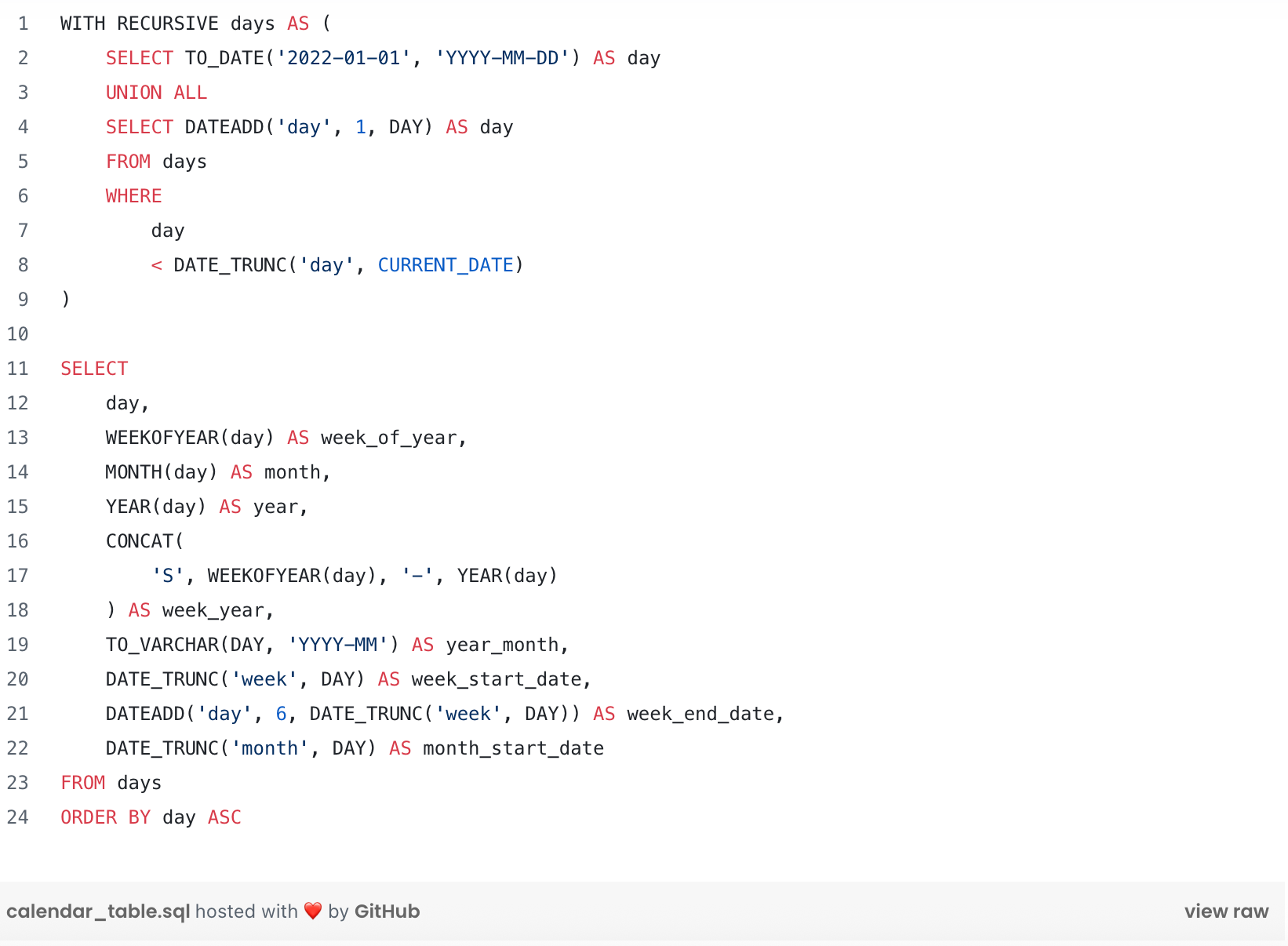
For example, for weekly or monthly aggregated KPIs, we built calendar tables. These temporal tables required a complete overhaul, but Snowflake’s advanced SQL features, such as recursive queries, made the work much easier.
Tips for a recursive calendar table with Snowflake SQL
Separating DEV and PROD environments
Given the lack of separate environments in the old architecture, we had to set up distinct environments for development and production to ensure that new features didn’t impact the production solution. To achieve this, we designed the Snowflake architecture by isolating environments and adjusting the impacted entities, such as schemas, databases, and warehouses. We created databases for each state of the medallion architecture and each environment: Silver, Silver DEV, Gold, Gold DEV.
With dbt, we defined targets in the profiles.yml configuration file, allowing modifications to be integrated into the development environment without affecting production. CI/CD manages the production environment by explicitly targeting behaviors for PROD - Merge.

To further automate the validation of impacts on data models, we introduced the create_volumetric_report macro. This macro generates a comprehensive report on key data metrics, including row count, distinct values, and null percentages, for each column in the model. This allows us to automatically check for any changes that could affect data quality across environments.

Quality tests and documentation
Migrating, testing, documenting: it seemed like a lot, yet we did it!
We started with a solution that had no tests, and we needed to detect and trace anomalies. The dbt documentation in yaml configuration files helped uncover previously invisible bugs. It significantly improved data quality and enabled the addition of documentation!
To ensure data compliance at the silver stage of the medallion architecture, we had to implement data quality tests. These checks validated non-null values and uniqueness! To verify our cross-referenced and transformed data, we implemented business tests and unit tests.
Data quality tests and documentation Each consumed data model is linked to a configuration file for tests, governance with tag of PII (Personally Identifiable Information) and documentation like this one. Dbt allows us to control data quality by executing these tests for each code base evolution. The unique command to run is dbt test. Failed tests are assessed, resolved, or prioritized to ensure the maintenance of data quality.
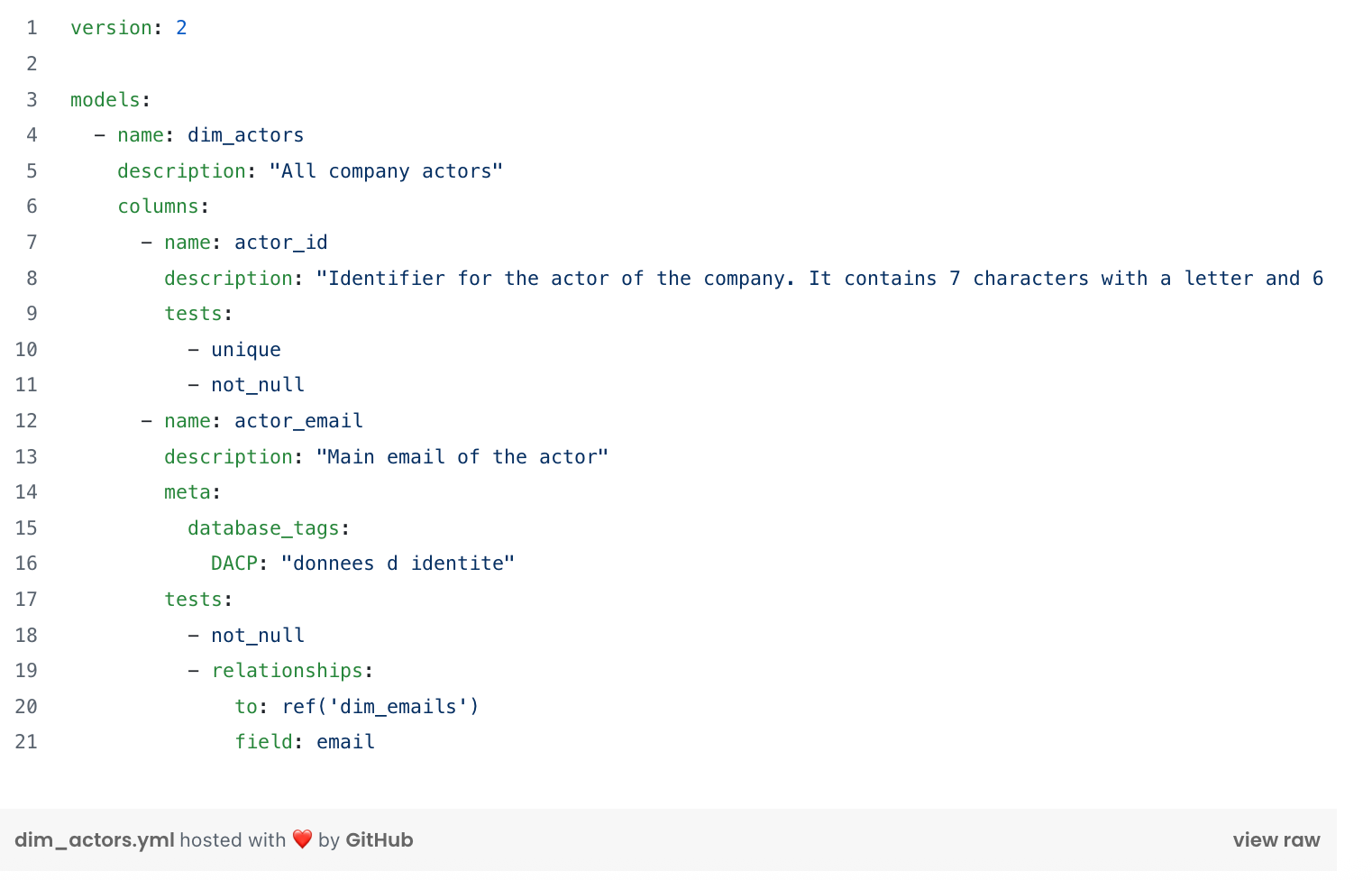
Unit testsDbt
Unit tests make it possible to test the behavior of SQL scripts in isolation by mocking input and output data and simulating the script's behavior.
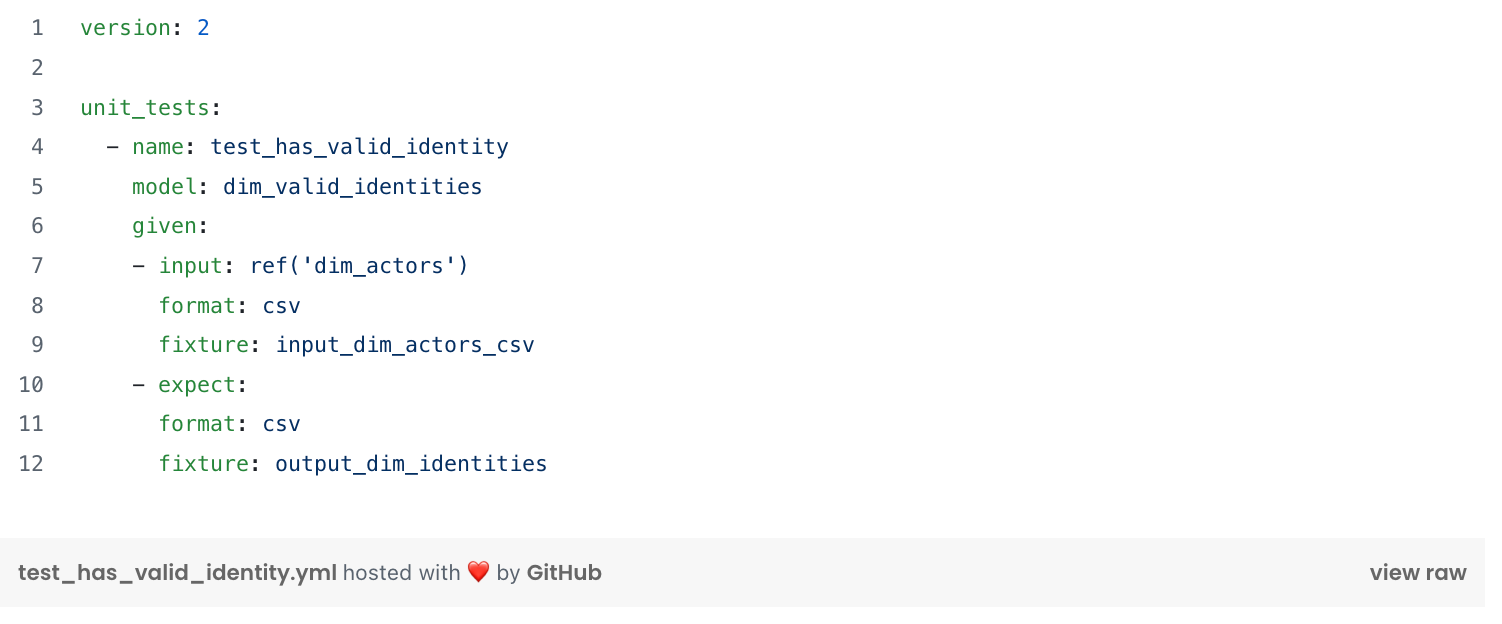
Custom tests
Custom tests allow us to verify the business rules we implement. They are called just like data quality tests in the configuration file of the tested model! The test is validated if no rows are returned when the following code is executed.
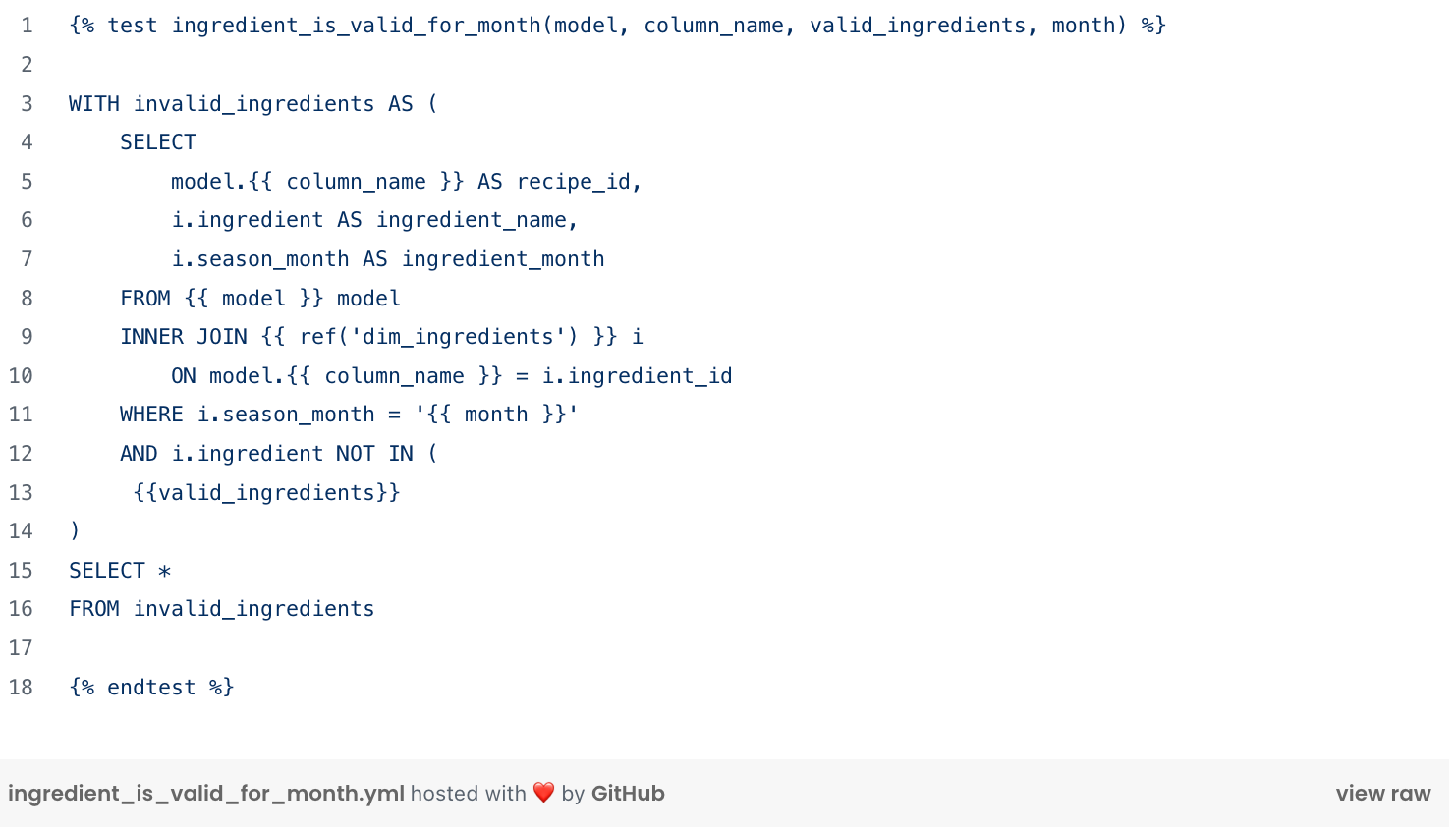
All custom tests are called in model’s configuration file. The test ingredient_is_valid_for_month is called on a model and its column in the model configuration yaml file. Following dim_actors configuration model illustration. For a deeper dive into monitoring dbt tests with Elementary, I recommend this article: Elevate Data Quality Checks with dbt and Elementary Integration Explored.
Our transformed data platform
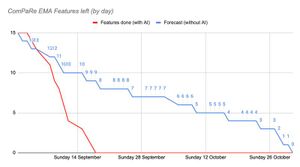
With Snowflake and dbt, the results exceeded our expectations. We can now develop and test a model in 15 seconds instead of 5 minutes, and without impacting PROD! We’ve increased data bug identification fivefold 📈 with 475 data quality tests! 🍾
Transformations are orchestrated in a modular and reusable way on dbt, allowing developers to have precise documentation and a clear understanding of each data model. 🎉 Now, we know what’s left to do: prioritize, log, and resolve the bugs.
What we learned from this migration
Setting up a collaborative development environment required creating specific roles and dedicated databases for each developer. These adjustments were essential to ensure a smooth migration and avoid conflicts.
And if we had to do it all over again? In hindsight, we would have strengthened role management by creating an omniscient role for developers and assigning each developer their own Snowflake database. 😱
It taught us that a successful transformation goes beyond simply moving data. It’s an opportunity to rethink practices, improve team collaboration, and strengthen governance. If you’re considering a similar migration, start with a detailed inventory, document each step, and iterate with consumers to align your understanding with their needs! 👫
Want to learn more or benefit from our expertise for your migration projects? Contact us today!
Article rédigé par Chloé Adnet